Greenplum: A Hybrid Database for Transactional and Analytical Workloads笔记
GP的HTAP路线是在一个AP的系统上加入TP的支持。
HTAP的几个路线
- OLTP到HTAP:Amazon Aurora,AP的支持是通过计算层支持分布式执行实现(扩并行能力来提升AP性能,存储不变)
- NewSQL到HTAP:
- TiDB(raft learner,行存转列存),F1 Lightning。
- GP:从AP演进到HTAP,具体做法见下面
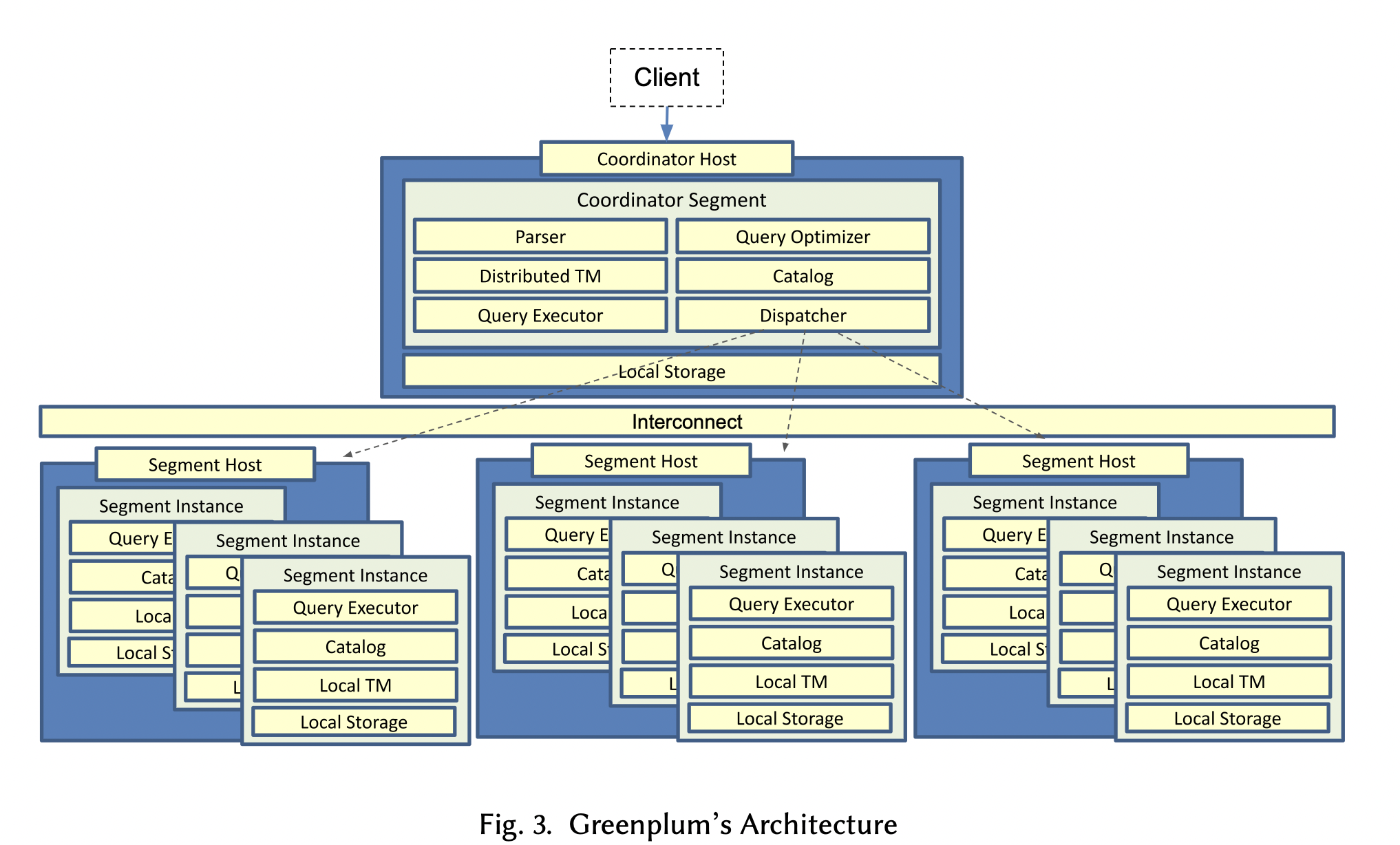
1 GP的MPP架构
1.1 整体架构
Coordinator Segment:只有一个,client和coordinator相连。coordinator从client接收sql语句,解析,生成分布式执行计划,分发执行计划到个个segment并收集结果,返回给client。
Segment:存储数据,执行分布式执行计划的一部分。
高可用,一部分segment可配置为mirror(standby),mirror不参与执行,只从Primary Segment接收WAL log,回放log。
GP是shard-nothing架构。
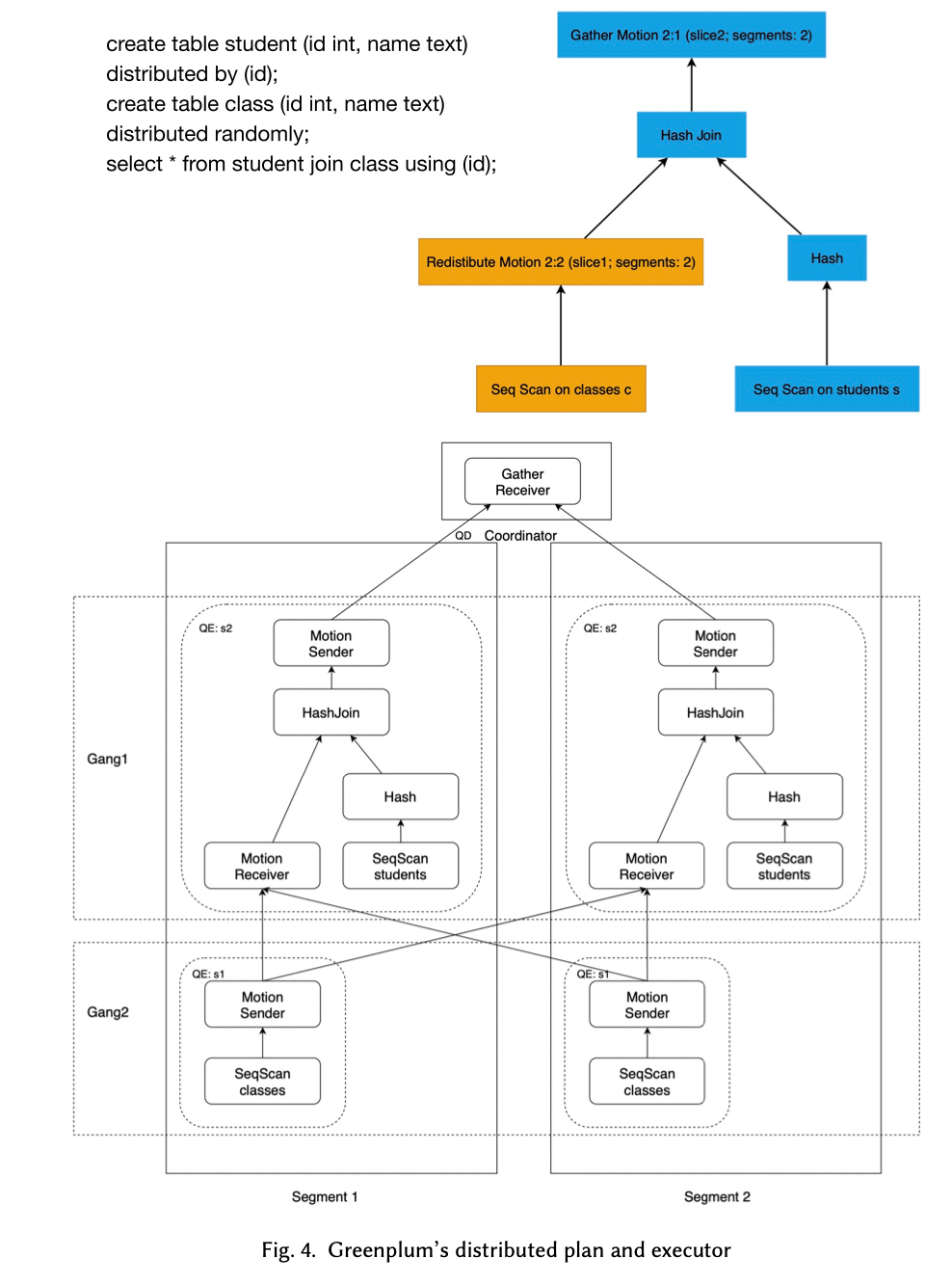
1.2 分布式执行
数据都是分布在segment中,当需要join两个表的时候,需要把一部分数据从一个segment移动到另一个segment。GP引入一个Plan Node叫做Motion来表示上面的数据移动,其实就是shuffle。
Motion Plan Node会把plan cut into pieces,每个piece叫做Slice。每个Slice被一组分布式process执行,这组分布式process叫做Gang。
执行过程就是SPMD(Single Program Multiple Data). 一部分plan分给一个gang,每个gang拿到相同的plan,但在不同的数据上执行。
QD(Query Dispatcher):负责每个query的执行计划执行,计划分发
QE(Query Executor) : 执行具体的执行计划
1.3 Distributed Transaction Management
每个segment运行一个enhanced PostgreSQL实例来保证单机可以commit或者abort transaction。
分布式方面,GP使用分布式snapshots和2PC协议来保证ACID。
1.4 Hybrid Storage and Optimizer
GP支持异构的存储引擎:
- PostgreSQL的heap table,行存,fixed size blocks + buffer cache。
还支持另外两种自研存储引擎:
- AO-row : Append Optimized row oriented storage
- AO-column: Append Optimized column oriented storage
AO的存储引擎相对于随机写,在AP场景下性能更好。
AO表可以压缩,AO-column表可以用更多的列存的压缩算法。
GP的Query execution engine对以上三种表是透明的,可以同时join不同类型的表。
2. Object Lock Optimization
GP中有三种锁:spin lock , LW lock, object lock.
Spin Lock和LWLock(light weight lock) 用作共享内存变量的互斥访问,只要保证锁获取的顺序都一样,就能避免死锁。
Object Lock锁住的是database中的对象,例如 relation, tuple,或者transaction。
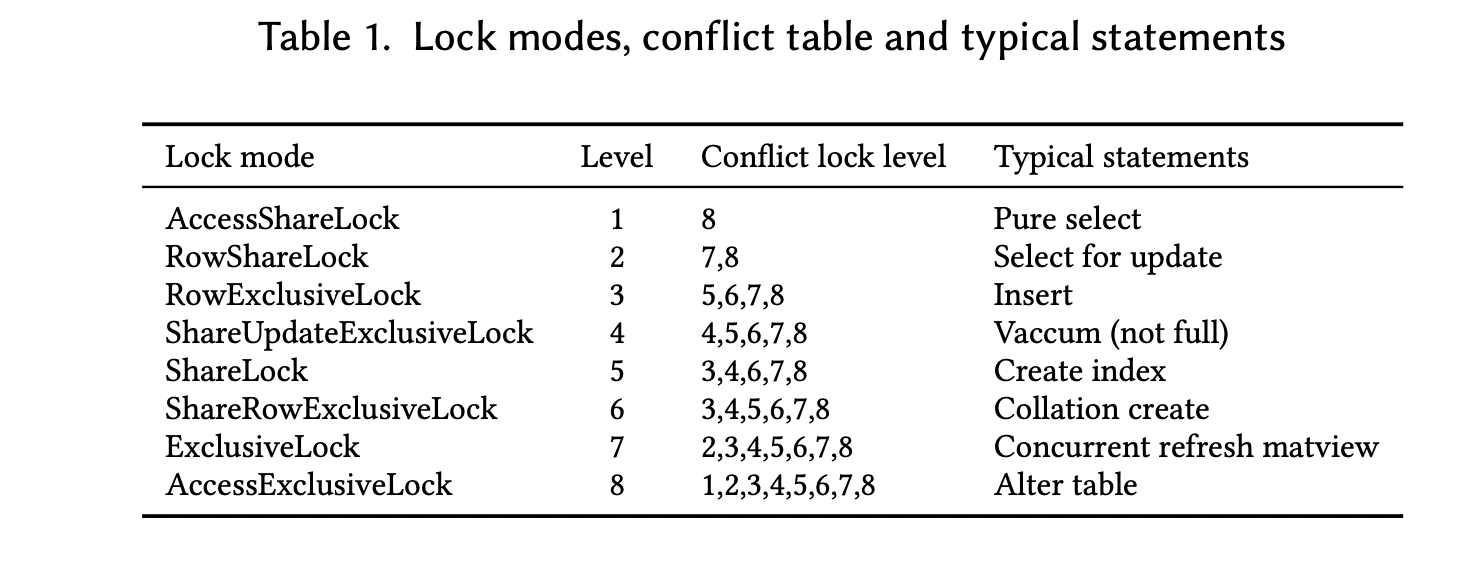
GP中的lock level和postgresql一样。level越高,并发力度越低。
2.2 Global Deadlock issue
在分布式系统中,INSERT,DELETE,和UPDATE DML的lock level至关重要,因为处理不当会出现死锁。
上面DML的locking行为如下:
- 在parse-analyze阶段,分析出需要lock的table,和使用的lock mode
- 在执行阶段,使用tuple lock。
在单segment的系统中(postgresql),第一阶段通常使用RowExclusive,提高并发(只有当同时UPDATE,DELETE同一个tuple的时候才会串行执行)。lock的依赖保存在内存中,当发生死锁的时候,很容易从内存中分析lock的依赖来打破死锁。
但在分布式事务中,会出现死锁问题。例如下图,txB和txA的lock出现了环形依赖。
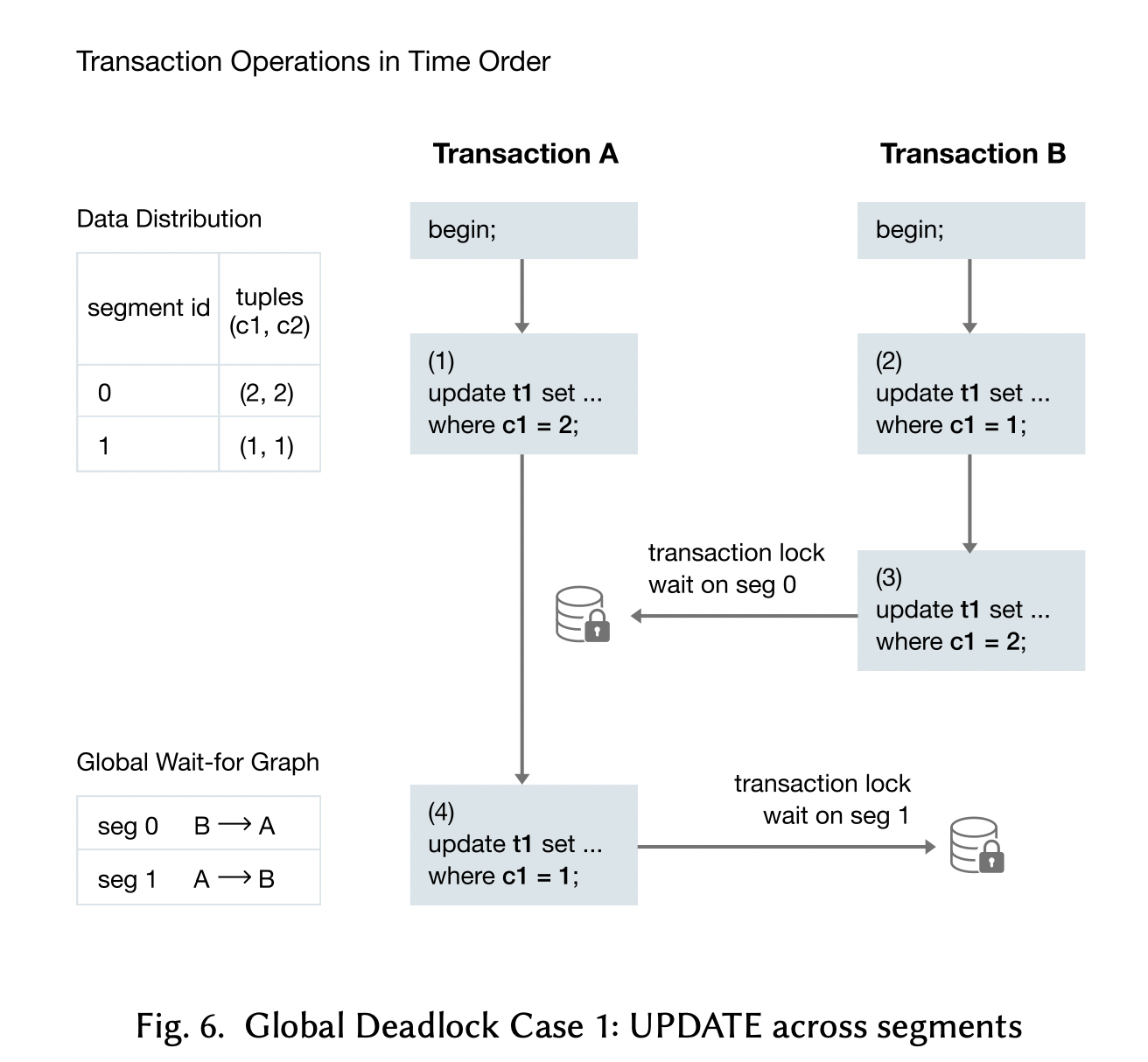
在GP5和之前的版本中,为了避免死锁,在coordinator的parse-analyse阶段,被写的表会使用Exclusive Lock(level 7)锁住,(在QE执行的时候不回在segment上lock和unlock),所以当多个tx同时update或者delete一个表的时候,其实是串行执行的,会导致OLTP性能的下降(因为不允许同时写一个表,即使写的tuple不是同一个)。
2.3 Global Lock Detection Algorithm
为了避免出现分布式情况下死锁。GDD(global deadlock detectioin)后台进程会收集每个segment(包括coordinator)的local wait-for graph,构建一个global wait-for grpah。
graph中的vertex表示一个transaction,edge从一个waiting-trasanction指向holding-trasaction。
graph中的edge可以有两种类型:
- solid edge:表示holding-trasaction执行结束后,才能释放锁
- dotted edge:表示holdinig-trasaction没有结束,也可以释放锁
死锁检测就是判断图中是否有环。不断移除degree为0的节点。
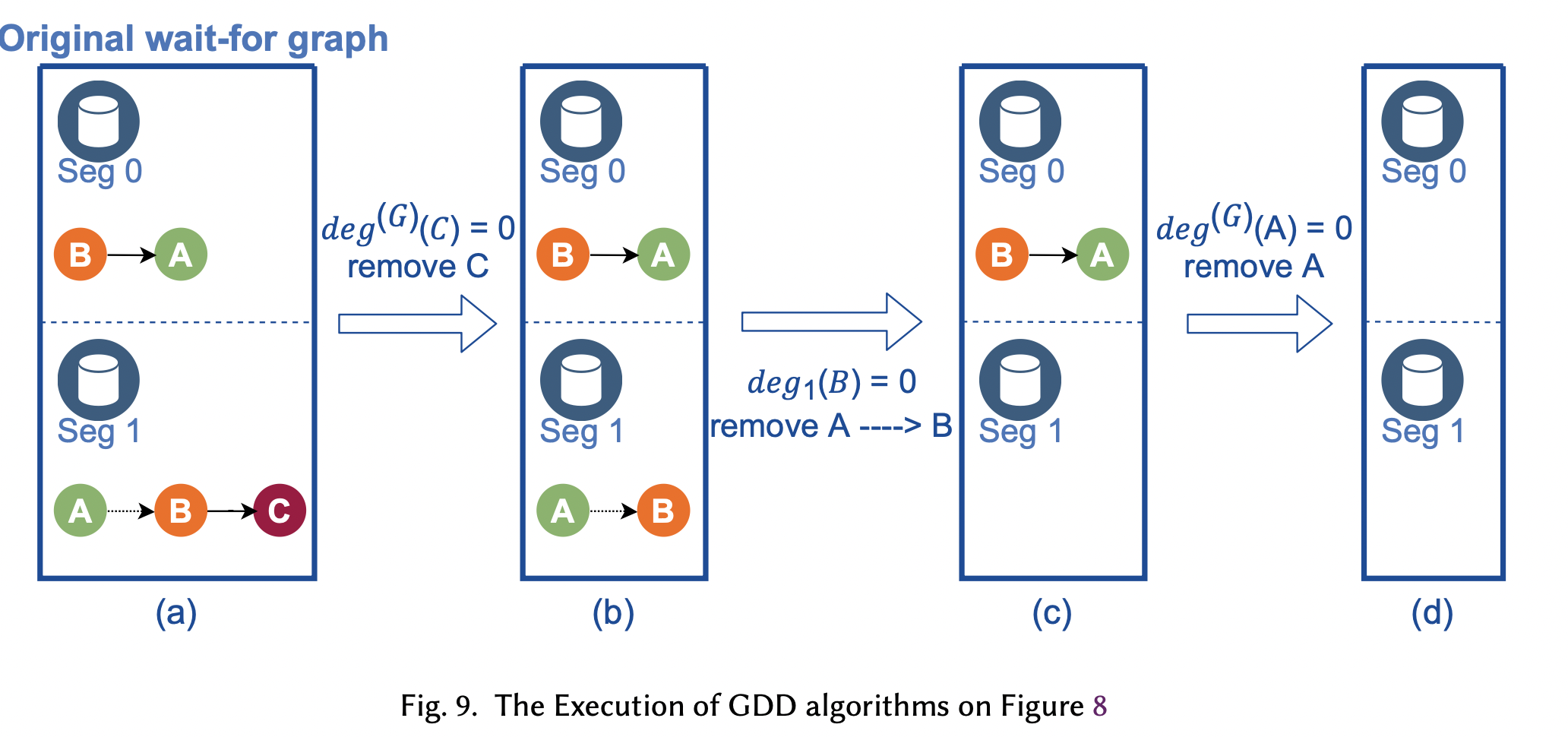
有了GDD算法之后,GP就可以把UPDATE,INSERT的lock level降低(相比GP5版本)。这样update 或者delete同一个表就可以并行在一起。GDD进程周期性的从segment获取wait-for graph,检测死锁,在通过某种策略(kill yongest transaction)来避免死锁。
3. Distributed Transaction Management
GP为每个事物分配了一个全局唯一单调递增的global txid,,相当于定义了一个顺序。
Segment的事物依赖postgresql的事物机制,segment也会为收到的事物分配一个loacl txid。
3.1 Distributed Transaction Isolation
PostgreSQL使用MVCC,GP类似,依赖global txid和PostgreSQL的snapshot实现了global snapshot机制。
每个tuple修改的时候会带上local txid,segment维护tuple->local txid -> global txid的映射。分布式的snapshot通过global txid查询到对应有local tx-id的tuple实现。
维护这个mapping开销比较大,实际上只维护了当前看到的正在运行的最老的transaction的映射关系。
3.2 One-Phase Commit Protocol
GP使用2PC来保证事物的一致性,但如果事物只会写/修改一个segment,可以把2PC优化为1PC,省区prepare,直接commit。
4. Resource Isolation
HTAP场景下,TP和AP会相互影响,主要是AP都是大查询,消耗比较多的cpu,会影响TP的正常运行。
GP使用资源组(Resource Group)的方式来对不同的workload和用户组的资源进行隔离。Resource Group对CPU和memory的隔离采用了不同的技术。
CPU隔离:使用linux的cgroup实现,cpu.shares指定CPU的使用率或者优先级,soft control: 如果当前没有正在执行的query,则会占用所有share。cpuset.cpus指定使用的cpu核数,hard control,指定cpu核数使用的上限。
memory隔离:GP实现了内存管理模块Vmemtracker来跟踪请求执行过程中的内存占用。当Resource Group的内存超用的时候,group内的query会被cancel掉。但实际上,精细的跟踪query内存使用情况比较困难,GP使用了一种更为robust的分层方式来做内存隔离:
- 第一层, slot memory,控制单个query在group中的内存占用。slot memory计算方式,group的非共享部分内存空间/并发度.
- 第二层,group shared memory,group内query可以共享的内存quota,当一个query的slot memory不够用的时候,可以占用这部分内存空间。
- 第三层,global shared memory,前面两层都不够用的时候,使用这部分内存quota。
建议的配置:TP配置更多的CPU,因为TP都是latency sensitive的。 AP配置更多的memory,因为AP相对TP使用更多memory,防止中间结果spill to disk。
Resource Group还需要配置Concurrency,表示一个resource group可以有多少connection连接到db。
TP往往需要高的concurrency。
5 Evaluation
GP6由于只有一个coordinator,在TP高负载情况下coordinator会成为瓶颈。