The Snowflake Elastic Data Warehouse
0x00 整体架构
Snowflake是一个三层的架构
- Cloud Service:整个系统的控制面,负责数据库元数据存储、访问控制、统计信息等。有状态。sql解析,生成执行计划,执行计划状态跟踪等。
- Virtual Warehouses:计算层,无状态
- Data Storage:使用AWS S3作为持久化存储层,有状态,存储表数据和查询过程中的中间结果等。
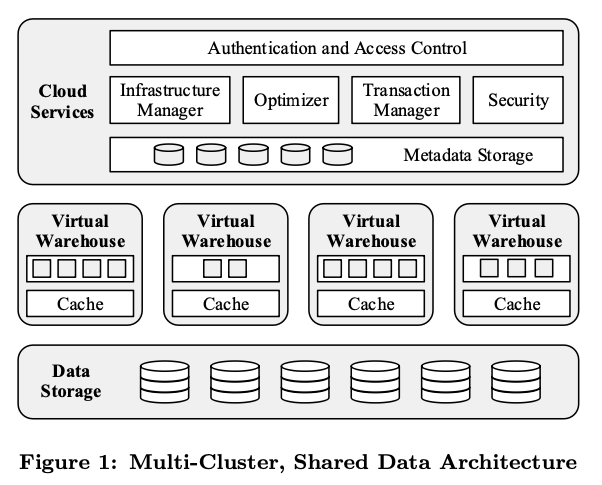
0x01 存储层(Data Storage)
虽然S3的性能不稳定,但是考虑到S3的高可靠和高可用方面没有其他竞争对手,所以Snnowflake最终使用S3作为持久化存储。
由于S3支持的操作有PUT/GET/DELETE,无法APPEND,但是可以GET部分文件,这个特性极大的影响了Snowflake表存储结构的设计。
- 表被水平(按照行)的切分成为很多个只读文件,类似于数据库中block或者page的概念。
- 每个文件按照PAX格式(行列混合存储)组织,如果要读取某列,无需读取整个文件。先读header,找到列offset,再利用S3支持GET部分文件定位到列。
- S3不仅用来做表存储,而且用来做查询过程中的中间结果存储(本地磁盘不够用的时候Spill到S3上),这样可以做到支持大表的join。
存储层的元数据信息存储在Cloud Service层的transactional key-value store(应该是fundationdb)中,元数据包括:
- 表中包含多少个S3文件,文件名是什么
- 表的统计信息
- lock
- transaction log
0x02 计算层(Virtual Warehouse)
弹性和隔离性
- 每个用户拥有一个Virtual Warehouse集群,保证不同用户相互不受影响。
- 使用EC2作为计算,可以做到弹性可扩展,无状态。当集群没有请求的时候,用户可以选择关闭整个计算层来节约成本。
- EC2按照时间计费,如果系统先行可扩展,可以通过加更多的机器来缩短计算时间,同时成本不会增加。
本地缓存和文件偷取
- 可以在计算节点上做文件的缓存,缓存PAX文件的header和读取过的对应列。
- LRU
- 使用一执行哈希来提升缓存命中。将文件哈希到VM的机器上。
- 当数据出现skew的情况时,使用file stealing的方式来让计算更为均衡。从S3上下载文件到本地(而不是从其他VM节点);缓存文件的所有权只在当前query执行期间拥有,不影响一执行哈希。
执行引擎
列式,向量化,Push-based。
0x03 控制面(Cloud Service)
Query Management and Optimization
所有的查询先通过Cloud Service层进行:parsing,query plan生成,plan优化,访问权限控制,最终执行计划发送给计算层。
随着query的执行,Cloud Service会监控执行过程中的统计信息(例如Performance Counter)和监测计算节点的失败情况。
Query的基本信息和执行过程中的统计信息会被记录下来用于后续的审计和性能优化。
并发控制
因为S3存储中的文件都是不可变的,所有的对表的修改,更新,删除都通过添加新的文件来完成,所以天然的可以保留多个数据的版本,使用MVCC来做并发控制。
文件的添加和合并都会记录在CloudService的元数据信息中。
查询过程中的数据访问剪枝
静态剪枝 : 由于数据是按照block/page组织的,所以可以针对block/page维护一些统计信息来避免整个block/page的scan。
例如维护block/page内某个字段的min和max信息,当出现类似 select * from table where age < 10 这样的语句时,可以通过访问min,max统计信息过滤掉一些不需要的block/page。
动态剪枝: 维护数据的分布信息。例如,对于hash join的一个优化是,snowflake维护了build-side record的key的分布信息,将该信息发送到probe-side,这样可以过滤/跳过不必要的文件。类似于Bloom-join算法:对小表构建bloom filter,将bloom filter分布式广播到大表上,大表先通过bloom filter过滤掉一些数据,再做join。
0x04 Lessons Learned
- 为了减少用户tunning database的麻烦,snowflake只有一个用户可调节的参数:用户到底需要多少的performance(对应的是用户预算)
0x05 总结
- 整体是三层的设计,存储使用S3,计算使用EC2(资源隔离比较粗),控制面用来做sql解析等。整个系统针对大查询设计。没有索引,大力出奇迹,文件的访问裁剪就很重要。
- 存储针对S3的特性(文件只读,不可修改)做了很多设计和优化。存储是文件级别的,和TP系统的KV级别存储不一样。
- 计算层无状态,如果系统性能线性可扩展,对用户而言,加机器可以保证在成本不变的情况下更快的算出结果。