Sortledton: a Universal, Transactional Graph Data Structure
这两年关于动态图存储/计算的文章层出不穷,Sortledton这片文章对以往的工作做了详细的分析,是一篇不错的summary,同时提出了一种新的动态图存储方式(in-memory),非常值得一读。
文章对应的项目代码在 这里; 对比各个动态图存储项目的benchmark在这里
0x00 背景
Graph相关的workload和对应的系统设计Choke Point可以分为以下几类:
- 图分析analytics(例如pagerank)和图遍历traversal(例如SSSP):系统需要支持fast scan
- 图模式匹配(Graph Pattern Matching),例如三角计数:为了性能需要,一个点的neighbor列表需要有序的,方便做集合求交集。
- 动态图:数据结构要求是可以动态修改的,(CSR就不行)
- HTAP,为了让图在修改的同时支持分析计算:数据结构要求支持多版本(例如MVCC)
已有的系统(除了Teseo)都无法很好的满足上述需求,Teseo的问题是系统采用CSR类似的结构来存储,比较复杂,同时Teseo论文中并没有给出使用CSR的好处在哪里(相比ADJ list)。
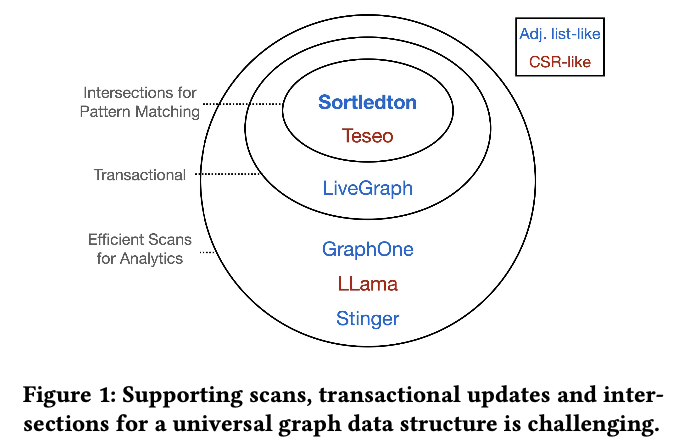
内存访问模式和相关benchmark特性
作者总结了图的workload中的四种经典的内存访问模式:
- sequential access to the neighborhoods of all vertices
- sequential access to the edges within a neighborhood
- random access to algorithm-specific properties, e.g. scores for PageRank or distances for BFS
- random access to the neighborhoods of all vertices(在图的traversal算法中比较常见,例如khop)
为了验证不同数据结构对算法性能的影响,作者分析了LDBC Graphalytics Benchmark中的几个算法,发现这几个算法对上述的数据访问模式非常有代表意义。
这几个benchmark算法可以认为是图算法中比较经典的,其他算法的访问模式和这几个算法类似。
- Analytics 算法:WCC, PageRank,Community Detection via Label Propagation(CDLP)
- Traversal算法:BFS,SSSP
- GPM算法:local clustering co-efficient(LCC) 类似于三角计数
上述几个算法都有2,3的访问模式,其中Analytics算法有1的特性。SSSP和LCC有4的特性,未经过优化的BFS也有4的特性。经过优化的BFS(ligra那篇论文的方法)有随机访问vertex和顺序访问vertex的模式,但是整个系统瓶颈在顺序访问vertex上(也就是1)。
为了支持上述算法,对图存储系统API的要求是怎样的
作者总结了一些数据访问的API,在这些API基础上可以实现上面的算法。
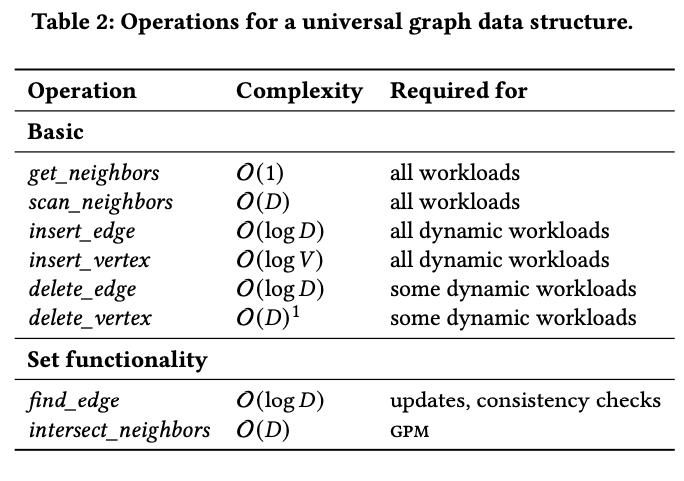
其中D表示节点的平均度数。
除了基础的操作外,作者认为提供Set的能力对于提升GPM算法很重要(具体可以参考AutoMine的文章)
- 保持neighbor列表有序,可以让intersect_neighbors复杂度从O(N*M)降低为O(D),因为有序集合求交可以做到这个程度。
- 保持neighbor列表有序,可以让find_edge复杂度也降低。二分查找。
另外上面的get_neighbors类似于seek到节点对应的neighbor列表的位置上,scan_neighbors表示iterate这个节点的neighbor列表。
对于图数据库,因为涉及到更为复杂的查询,例如按照属性过滤,应该需要提供更多的API,但这片论文主要考虑的是在动态图上进行图计算(也就是实现benchmark那几个算法),所以上述接口是足够的。
但这个设计对于图数据库的设计其实很有启发意义,因为图数据库中的最重要的操作就是pattern matching了。
0x01 动态存储结构之争:benchmark不同数据结构对性能的影响
这里作者做了很详细的benchmark,目的是验证动态数据结构相比静态数据结构的在benchmark算法上有多差?为了支持图的动态修改,要牺牲多少性能?
第一类模式:Sequential Vertex Access : CSR or Adj List
使用CSR数据结构作为baseline。对比CSR和Adj List对性能的影响。
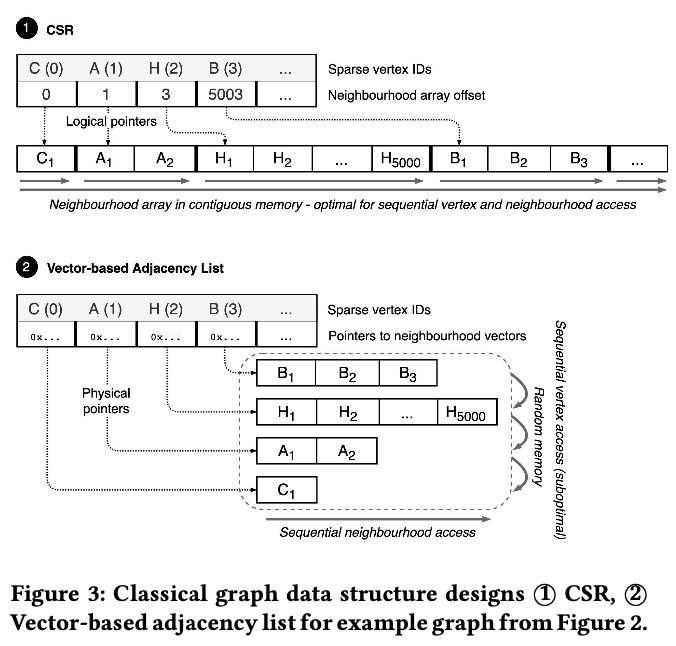
理论上CSR结构性能是最优,但是CSR是静态的,对插入和删除不友好,那CSR性能到底有多好?
CSR的访问都是顺序的,Adj list的访问neighbor是顺序,但是节点是随机。
结论:CSR相比Adj List的结构不会有非常显著的提升。因为整个系统的瓶颈在邻居访问上,两者都是顺序访问邻居。
第二类模式:Sequential Neighborhoods Access : Vector-based adj list or block-based link list
为了比较neighbor顺序访问对性能的影响,实现了两个数据结构进行测试:
- 使用vector-based adj list,邻居存在一个vector中(连续的内存)
- 使用unrolled linked list,邻居存储在链表中,链表每个元素是一个chunk(包含若干neighbor)
调整block的size测试性能。
结论:当block大小为256以上的时候,两种数据结构性能差别不大。
如果链表是有序的,可以做到插入的复杂度在O(log D),但是vector-based就无法同时做到neighbor有序和插入复杂度低。
第三类模式:Random Access to Algorithm Properties:使用Array还是哈希表来存储算法相关的属性?
算法相关的属性往往通过节点ID来索引。节点ID有两种:dense和sparse。
dense的节点ID范围在(0,V)之间,这样可以通过申请一个数组,然后通过下标来访问节点的属性。但dense domain的方式有两个问题:1. 节点删除后,属性的处理比较复杂 2. 上层应用需要保证id是dense的。
sparse的节点ID范围是任意的,可以通过哈希表来存储节点ID到属性的映射。哈希表是动态的,比较有利于增删。
benchmark显示,dense domain的方式比sparse domain的方式最多有6倍性能提升。
结论:任何图计算系统都需要使用dense domain的方式来存储结构和属性(处于性能考虑)。针对动态图的场景,需要设计sparse id到dense id的动态管理机制来满足动态图的要求。
其实neo4j和tiger都会存在一个id server来干这件事。
第四类模式:Random Vertex Access:使用Array还是哈希表来索引拓扑结构?
在tranversal算法下,节点的访问往往是随机的,例如SSSP。如何快速定位到给定节点的neighbor列表?
- 使用dense domain的方式,使用ID作为offset,定位到节点的neighbor列表
- 使用哈希表存储节点id到neighbor列表的映射
结论:哈希表会带来1.1到3倍的性能下降。
总结一下:如果动态存储结构性能要好,需要满足
- 保证邻居是有序的,有利于GPM
- 邻居使用block的方式存储,保证邻居访问是顺序的
- id 映射是必要的
- 对于random vertex访问,需要高效(low latency)的索引结构
0x02 图上的事务(Tx on Graphs)
事务Workload是什么样子的?
Graph的Workload往往是读多写少,并且读写混合的事物往往是非常简单的。(此处有作者引用的论文作为证明)。一般来说,读的query是非常heavy的,例如图分析任务和GPM任务;写的事物往往是添加一条边,因此是非常简单的。
但是,也有非常复杂的事务,SQL标准添加了graph事务的扩展(GQL),GQL支持了非常复杂的写事务,例如构造一个图,这种情况下事务的readset和write set会访问到大量的数据。
如果按照workload事务的出现频率,从高到底可以分为以下几种:
- 长时间运行的复杂只读事务,例如图分析
- 短并且简单的读写混合事务,提前知道write set
- 复杂的读写混合事务,可以有任意大小的并且提前无法预知的read-write set。
Sortledton系统只处理前两种事务类型,其中第二种可以利用关系型数据库的事务处理方法来解决。
一致性要求
大部份图系统对数据的一致性要求如下:
- 没有悬挂边,一条边的起点和终点必须存在。(ID service这里会有这个要求)
- 没有重复边。(金融场景下可能存在重复边,个人感觉这个要求有点强了)
- 对于无向图,正向边和反向边同时存在。
所以在write-only的tx种,会隐式的包含read set(read set可以通过write set推断出来,例如插入A->B的边,要求读A和B)。
对系统设计的要求 - Versioned Storage
Graph database种每个entry的数据非常小(例如一条边只占用4或者8个byte),因此,图存储需要对没有版本的record不引入任何存储开销,同时对有多个版本的record引入非常小的开销。
其次,系统应该对有一个或者两个版本的情况做特殊的优化,因为大部份情况下一份数据只有一到两个版本。
0x03 进入正题:Sortledton的存储结构设计
上面说了那么多,Sortledton的存储是如何设计的呢?
首先,Sortledton只针对 memory access pattern中的2,3,4进行优化设计,因为sequential vertex access其实在图分析中不是瓶颈,只要保证neighbor访问是顺序的就能带来不错的性能。上面的microbenchmark也证明了这点。
其次,Sortledton的存储设计不会存在后台的进程来做数据整理,因此也不会出现读时合并,对读比较友好。
选择Adj List来存储图结构,而非CSR
adj list的存储结构有如下好处:
- 图计算时可以实现节点级别的数据并行,embarrassingly parallel
- 相比CSR,adj list的数据更新更为高效。这也是论文diss Teseo的点
- adj list的设计可以解构为:设计map索引和邻居set存储,然而这两个点是well study的,可以直接利用已有数据结构成果。
存储结构:adjacency index + adjacency sets
adjacency index保存vertex id到vertex record的映射,vertex record包含以下信息:
- pointer to the neighborhood
- neighbors size
- read-write latch for parallelism
adjacency index使用了vector结构来保证可以快速seek到vertex record。为了避免在vector扩展的时候出现全局锁,vector设计为两层的:第一层是fixed size,value 是指向第二层vector的指针;第二层的vector也是fix size,是按照2的幂次大小。

也就是vertex的集合被划分为了若干个segment。segment的大小是2的幂次增长的。
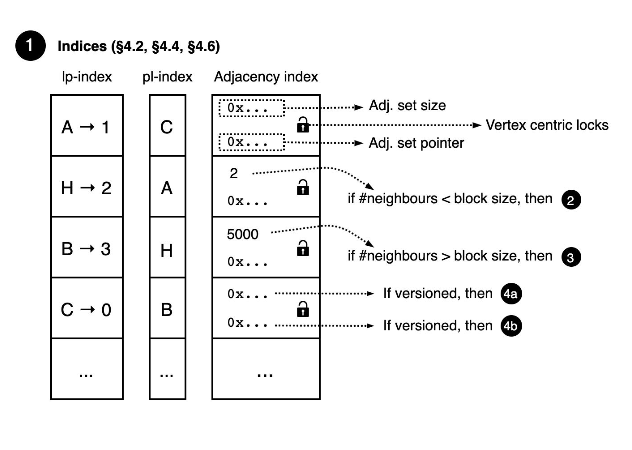
adjacency sets : 保存每个节点的neighbor列表,使用了unrolled skip list,un rolled skip list中的每个元素是header信息 + 一组边(block)数据。block其实就是一个数组。header信息包括:当前block中边的数目,当前block中id最大的目的节点,skip list中的各个level。block内节点id是有序的。
block的分裂和合并:当block充满后会分裂为两个,当相邻两个block使用率少于一半时会合并为一个。
find_edge: 首先按照skip list算法找到对应的block,再block内通过二分找到对应的边。
插入/删除:最多移动 block_size 个neighbor。因此复杂度为O( max(log D, block_size ))
上面的microbenchmark也证明了当_block_size_ 大于128的时候可以认为是sequential access了。
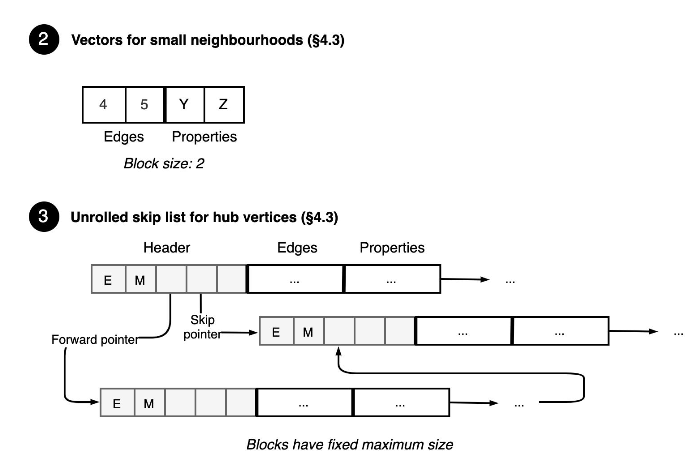
unrolled skip list对于hub vertex这种超级节点是友好的,由于数据是幂律分布的,因此对于小节点要特殊设计。
当neighbor数小于_block_size_的时候,使用没有header的,2的幂次方大小的vector存储neighbor列表,如上图。这样插入和删除的复杂度为O(block_size)
vertex identifier translation : microbenchmark已经证明了,使用dense domain的id表示可以提升性能,所以id transation必不可少。对于性能敏感的计算,应该使用dense domain来计算,输入输出则通过id transation来做转换。
concurrent hash set来做sparse到dense的id转换,concurrent two-level vector 来做dense 到sparse的id转换。
edge properties : 因为大部份workload不会访问边的属性,在这里将边和属性分开存储,边的属性按照边的顺序存储在block的尾部。
数据的并行访问过程中的线程安全
vertex中存储了read-write latch来对并发的读写进行保护,实现过程中保证了latch的全局顺序来避免死锁。
对于hub vertex的特殊处理:对每个block维护一个latch,避免锁的竞争。对于读操作使用optimistic latch。
0x04 事务中的并发控制
WAL来保证可持久化。
多版本存储: edge version record = operation type(insert, update, delete) + commit timestamp + property。
edge block中,一条边的多个版本按照链表的方式串在一起。adjacency set和vertex的多个版本也是类似。
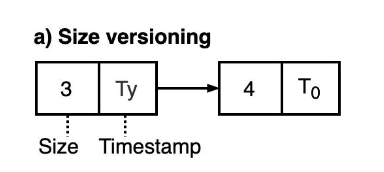

在这里针对两个以内的version做了特殊优化。对于只有一个version的edge,不会保存version record,所有的操作都会赋予T0的时间戳。对于两个version的edge,将version record inline到了block中。
如果没有version record,edge在block内的正向offset就是property的反向offset;如果有version record,因为本身要占用一定的空间,因此需要重新计算property的反向offset。多个version的时候访问edge property会有一定程度的变慢。但benchmark算法基本上没有访问edge property的,所以sortledton系统对这方面优化比较少。
并发控制:
- 只读事务:使用ROMVCC,获取read lock,read, unlock。
- 对于读写事务:使用2PL,获取所有lock,读数据,获取时间戳,写数据,unlock。
GC:
- 找到要回收的ts:维护当前正在运行的tx的时间戳,找到没有tx访问的时间戳进行gc。
- 回收:执行写tx的线程负责回收ts
相比于开一个后台线程定时去做gc,这种eager的gc可以避免很长的version chain。
0x05 实现上的两点优化
-
dense id对性能影响很大,对input将sparse id 转为dense id,计算结果的output再转回来。因为input和output一般都比较小,所以id translation开销不大
-
访问neighbor的时候
- 可以用iterator的方式
- 传入lambda,对每个edge apply 这个lambda
- 直接裸内存访问
对于没有version record的block,3的方式相比1和2最多带来2.3x的性能提升。因为1和2访问每条边的时候要多调用1到2个函数(iterator.next())
0x06 Evaluation
在单机,2x14physical thread, 256GB内存上做的实验,实验过程中 disable disk-logging for all systems ,也就是可持久化部分是缺失的。。。。主要比较各个系统的性能。应该是如果enable 了disk logging,insert和update的瓶颈在disk logging上了。
256GB的内存,实验使用最大的图是friendster,29M节点,2B边,CSR表示下大小为67GB,如果内存压缩的好,是可以满足的。
作者对比了插入,更新,多核可扩展性,图计算,更新的时候同时图计算的性能。注意,做实验的时候disable了disk logging。
实时写入
对friendster数据,sortledton可以达到大概4.2M eps(edge per second)的实时写入性能。而GraphOne如果插入的时候加入对边的检查(禁止插入悬挂边,禁止重复插入边),性能降低到5 eps。因为sortledton对检查边是否存在更为高效O(log D)。
上面实验是随机插入边,对于顺序插入边(插入的时候按照src节点顺序插入边),Sortledton, LiveGraph,LLama性能都会下降,因为是vertex level的locking,lock的竞争更为强烈。而GraphOne和Stinger影响不大,因为使用了batch update或者lock-free的方式。
实时更新
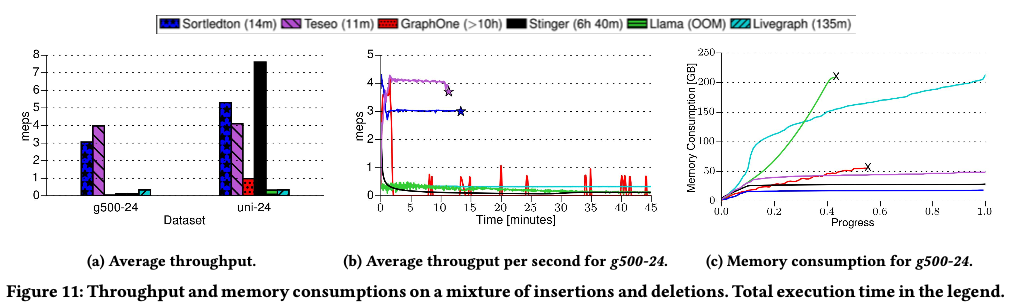
setup:前10%的操作将 Graph500-24这张图导入,后续的90%操作是insert和deletion,同时保证整个graph的大小是稳定的。
- 平均吞吐:对比实时写入,可以看到deletion对整个吞吐的影响。LiveGraph和Stinger将deletion看作是一个特殊的insert(记log),因此对性能影响不大。Sortledton吞吐变小(3.8M eps -> 3M eps),因为创建和维护version chain的开销不可忽略。Teseo性能变好(3M eps -> 4M eps),因为deletion会马上释放空间,减少B+tree的rebalance。(不是很懂这里)。 LLama性能砍半,GraphOne性能降低了64倍。。。。
- tput-时间曲线:sortledton曲线最开始下降,后面逐渐平滑。当数据导入结束后,后续的delete和insert因为是inplace的,不会让数据规模变大(相比记log,然后merge on read的方式),所以平滑。这里说LiveGraph也是写时合并,但个人认为是错误的,因为livegraph是merge on read,所以频繁的更新都会以log的形式体现在文件上,这样随着操作的增加,文件大小变大,写时的检查会导致性能下降(读慢了)?但livegraph主打pure sequential scan,所以如果sequential scan的话对性能无影响?GraphOne性能非常不稳定,并且tput很低。。。。作者分析主要因为GraphOne在findedge性能很低。
- 内存开销:取决于256GB内存能装下多大的图。Sortledton当数据导入完成后,后续的更新操作不会引起内存增长。毕竟in-place update。 同时内存使用率也挺高的,8.3GB的CSR的图,Sortledton存储使用了18GB,相比48GB(Teseo)和27GB(Stinger)很低了。LiveGraph因为是记log,所以内存开销一直在涨。
以下是我的思考:
- 作者的实验都是disable disk logging下做的,如果enable了持久化,结论可能会不一样。
-
Merge on write的方式对读友好,同时更新的性能会更稳定一些,工程实现好的话,可以比Merge on read的更新性能更好。LiveGraph和GraphOne都是Merge on read,所以在遇到频繁更新的时候,因为图的特殊性(插入edge要检查1. edge是否存在 2. 禁止悬挂边),所以对性能的稳定性影响很大(tput-时间曲线),当然不排除他们工程实现的不好。。。GraphOne如果不做一执行检查,插入性能也很好。
- Sortledton证明了动态图的存储开销相比CSR大概在2倍左右。
- 插入/删除edge的时候,是否要做检查(1. edge只存在一条 2. 禁止悬挂边),再系统设计的时候要特殊考虑,对于性能影响很大(LiveGraph,GraphOne)
图计算性能
作者证明了Sortledton相比CSR在图计算上性能差不多。
图计算的同时加入图的更新(动态图上的计算)
Sortledton更偏向于AP的系统,所以实验给我感觉更像是在做图更新对图计算的影响。而不是在一个TP系统上,AP对现有TP系统的影响,例如对于TP系统,不能因为跑一个AP任务而把TP系统搞挂了,timeout了。
莫非真是世界的图的应用场景更倾向于是AP?TP只是为了数据更新?
在这里作者只对比了LiveGraph和Sortledton两个系统。
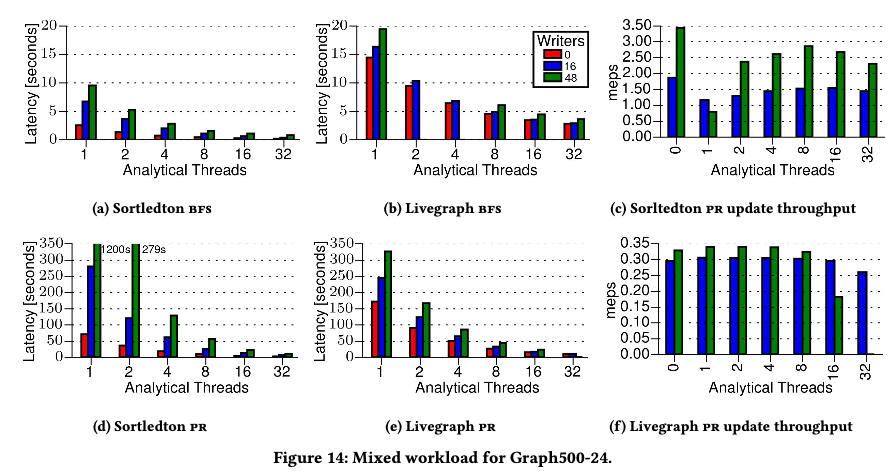
BFS因为只touch一部份数据,所以影响不大。PageRank因为要读整个图,所以会不一样。
对比图d和e,可以看到随着writer线程数增加,livegraph的图计算性能影响不大,但是sortledton影响很大。sortledton因为version chain变长,从访问raw memory退化为访问version chain,长的version chain影响读的性能;但是当计算线程变多,sortledton的读锁时间变短,version chain也会相应的变短,计算性能提升。 livegraph影响不大因为1)更新都是记录log,对读影响不太大 2) 记录了所有edge的version,性能不高。我们也从图表中可以看到,当计算线程变多,sortledton性能是优于livegraph。
0x0F 总结
这篇文章的microbenchmark做的很详细,解释了当数据结构从静态变为动态的时候,对性能的影响是怎样的。在evaluation部分对各个系统的性能问题也做了很好的总结。
首先,ID translation很重要;其次,ADJ优于CSR,CSR的唯一优势是sequential vertex access,但大部份算法对这部份性能不是瓶颈,保证edge的sequential access和order、减少vertex seek的时间很重要。最后,evaluation部分可以看到TP对AP的影响到底有多大,个人觉得缺乏一个AP对TP的影响,实际生产环境上,如果在运行图计算的时候,对TP的查询的吞吐和延迟影响,这部份论文并没有讨论,可能现在应用场景都是在动态图上做分析?
整体上这篇文章尝试去解决基于内存的动态图上的图计算,对图数据库的设计很有借鉴和参考的意义。文章整体偏向于AP的性能优化,evaluation部分也说了,在做实验的时候 disable disk-logging for all systems。 如何设计基于hdd/ssd的可持久化存储结构并没有做讨论。
要想性能好,还是得in-place update,对于更新,记log然后merge on read对性能影响还挺大。